{kind=link}

- DNA testy
- Rozšíření Mental HealthLorem ipsum dolor sit amet, consectetur adipiscing elitŠpecializované DNA testy
-
- Konzultace
- Kardiologická preventívna prehliadkaLorem ipsum dolor sit amet, consectetur adipiscing elit
-
- O nás
- Blog
Deoxyribonukleová kyselina, ve zkratce DNA, je nositelkou genetické informace a nachází sa v jádře téměř každé buňky v našem těle. Můžeme si ji představit jako „knihu receptů“, ve ktoré jednotlivé recepty představují geny. Díky genomu si dokáže buňka vyrobit výsledné produkty, což jsou ve většině případů proteiny. Ty v našem organismu následně zabezpečují různé úlohy, od stavebních, regulačních, transportních a mnohých dalších. Pokud se v těchto receptech (genech) vyskytne nějaká chyba, výsledný produkt může mít jiné vlastnosti, případně se nemusí vůbec tvořit. Tyto chyby označujeme jako „mutace“ a právě ty jsou ve velké míře zodpovědné za různé odlišnosti v našem organismu.
Co konkrétně se píše v těchto receptech se nám podařilo odhalit až začátkem tohoto století, kdy vědci přečetli celý lidský genom. Ten se skládá z přibližně 3 miliard stavebních bloků, které označujeme jako tzv. „nukleotidy“. Celá sekvence DNA je poskládána ze 4 základních nukleotidů – adenin, guanin, cytosin a thymin. Z tohoto důvodu se při sekvenci DNA setkáme s písmenky A, G, C a T. Samotný sled písmen nám však nic neřekne. Dnes již víme, že geny tvoří jen přibližně 2 % lidského genomu a máme jich přibližně 20 000. Zbytek více-méně neznáme, i když víme, že i v této části se nacházejí důležité oblasti pro správné fungování našich buněk.
Naše DNA se mezi námi shoduje až do míry 99,9 %. Na první pohled se může zdát, že se téměř nelišíme. Pokud se však vrátíme k velikosti našeho genomu, zjistíme, že se lišíme v přibližně 3 milionech nukleotidů. A právě tyto místa, na kterých se v populaci nacházejí různá písmena, jsou obrovským zájmem mnohých studií. Díky těmto studiím dnes dokážeme například říct, že pokud se u vás vyskytuje na konkrétním místě v DNA nějaké konkrétní písmeno, potom máte zvýšenou genetickou predispozici k rozvoji nějakého onemocnění, jako je například melanom nebo infarkt myokardu.
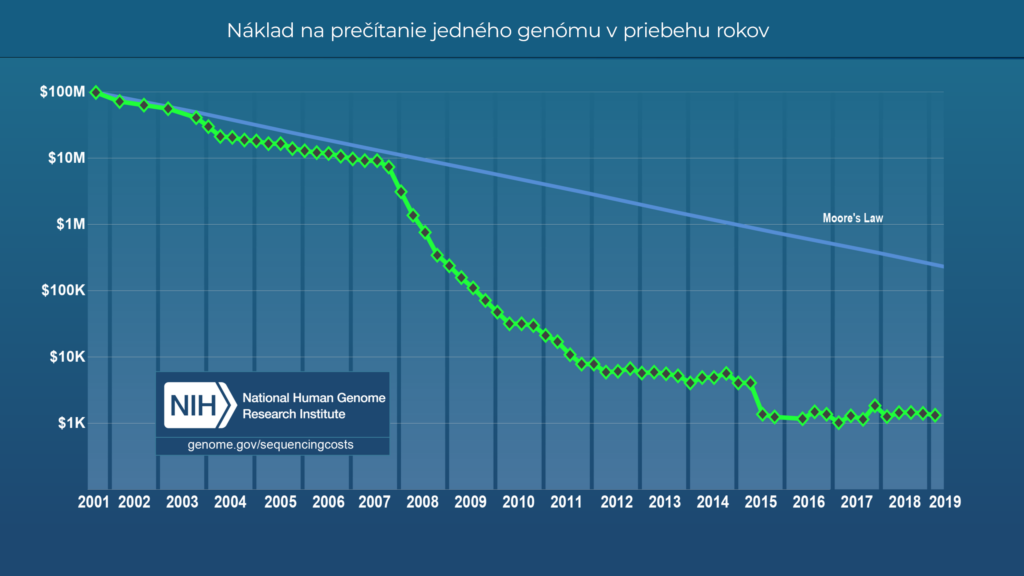
V současnosti jsou využívány hlavně dva způsoby čtení DNA – sekvenování a genotypizace.
Jednou z technik využívaných ke stanovení sekvence DNA je tzv. sekvenování, tedy určování pořadí nukleotidů v genomu jednotlivce. V současnosti se využívají zejména dva přístupy, a to tzv. celoexomové a celogenomové sekvenování.
Technologie celoexomového sekvenování je zaměřená jen na konkrétní místa v genomu, které poskytují informace na výrobu proteinů. Předpokládá se, že tyto části, nazývané jako „exony“, tvoří přibližně 1 % genomu člověka. Společně všechny exony v genomu jsou známy jako „exom“, a proto je jejich způsob sekvenování známý jako celoexomové sekvenování. Tento přístup umožňuje identifikovat mutace v kódující oblasti jakéhokoliv genu, a ne pouze v některých vybraných genech. A jelikož se většina známých mutací způsobujících onemocnění vyskytuje právě v exonech, tento způsob sekvenování je efektivní v identifikaci takovýchto potenciálních mutací.
Je však známo, že i mutace mimo oblasti exonů mohou ovlivnit genovou aktivitu a produkci bílkovin, a tím pádem mohou vést k různým onemocněním. Právě proto je nejideálnějším způsobem celogenomového sekvenování, které určuje pořadí téměř všech nukleotidů v genomu jednotlivce.
V současnosti je nejběžněji používanou metodou tzv. ILLUMINA sekvenování, díky kterému vzniklo více než 90 % všech sekvenačních dat na světě. Název této metody odkazuje na americkou společnost, která se podílí na vývoji, výrobě a prodeji systémů pro analýzu genetických variací a biologických funkcí, a která tuto metodu komercionalizovala.Tato metoda je založena na detekování jednotlivých nukleotidů (A, G, C a T) poté, co se začlení do rostoucího vlákna DNA. Detekce nukleotidů je založena na fluorescenčním signálu, to znamená, že každý nukleotid je označen nějakou fluorescenční značkou (můžeme si ji představit jako nějakou barevnou značku) a po přidání se do řetězce počítač vyhodnotí daný signál.

Momentálně ještě nejsme v bodě, kdy by stačilo přečíst celý lidský genom jen jedenkrát. V současnosti totiž ještě nejsou tak přesné sekvenační metody, které by dokázaly jen během jednoho čtení přečíst bezchybně celý genom. Právě z tohoto důvodu doporučuje společnost ILLUMINA minimální pokrytí 30x. To znamená, že v průměru je každý nukleotid přečten nezávisle 30-krát.
Některé společnosti však dnes nabízí i celogenomové sekvenování s mnohem menším pokrytím, v některých případech dokonce s pokrytím jen 1x. Při sekvenování s tak nízkým pokrytím je v současnosti nereálné přečíst celý genom. Jak je potom možné poskládat celou skládačku, když z čtení nejsou k dispozici některé dílky?
Tento proces je poměrně složitý, ale jednoduše se využívá princip tzv. „imputace“. Tímto způsobem se statisticky doplní nepřečtená místa, a to na základě známých haplotypů v populaci. Využívá se tu to, že jednotlivé nukleotidy se nedědí samostatně, ale dědí se společně ve skupinách, které označujeme jako „haplotypy“. Aby jsme však mohli považovat sekvenování s tak nízkým pokrytím za relevantní, je nutné mít velký a populačně specifický referenční panel, na základě kterého bude možné doplnit chybějící dílky genomu jednotlivce s vysokou přesností. Avšak i při splnění těchto podmínek není tento přístup vhodný pro analýzu velmi vzácných genetických variant.
V klinické praxi sa častokrát nesekvenuje celý genom, ani exom, ale sekvenují se jen konkrétní vybrané úseky – konkrétní geny. Toto diagnostické vyšetření je účinným nástrojem potvrzení nebo vyvrácení nějaké specifické patogenní mutace vedoucí k nějakému závažnému onemocnění, které se ve větší míře vyskytuje v rodinné historii daného pacienta.
Přestože nám celogenomové sekvenování poskytuje nejlepší obraz o našem genomu, stále patří mezi relativně drahé metody. Právě proto se v současnosti v komerčních testech DNA využívá zejmén přístup tzv. genotypizace, a to z důvodu její efektivity v poměru cena/výkon. Jde o analýzu konkrétních míst v DNA na čipu. Na rozdíl od celogenomového sekvenování sa tedy nečte celá DNA, ale jen konkrétní místa, které byly vybrány na základě toho, zda o nich něco víme a tedy zda je dokážeme s něčím asociovat. Tyto místa zahrnují například mutace spojované s různými onemocněními nebo s atletickým potenciálem. Více o tom, jak probíhá genotypizace, si můžete přečíst v tomto blogu.
Jak bylo už zmíněno výše v textu, samotný sled nukleotidů v genomu nám nic neřekne, klíčová je asociace konkrétních změn s konkrétními znaky.
Celogenomové sekvenování sice poskytuje nejucelenější pohled na genom jednotlivce, avšak musí být provedeno kvalitně, s dostatečně velkým pokrytím. To je však stále poměrně nákladné, a proto v kombinaci s tím, že v současnosti neznáme funkci většiny míst v genomu, nemůžeme dnes považovat tento přístup za efektivní pro komerční genetické testování.
Při genotypizaci se neanalyzuje celý genom, sledují se jen vybraná místa se známou funkcí. Tento efektivní přístup umožnil snížit cenu za genetické testování natolik, že se stal vhodným nástrojem pro komerční využití. Právě proto využíváme tento přístup v našich testech DNA i my v DNA ERA.
Zdroje:
Zdroje fotografií: